
یادگیری تقویتی یا Reinforcement Learning نوعی از الگوریتم های یادگیری ماشین است که با فرایندهای تصمیمگیری متوالی سروکار دارد و شامل یک عامل (Agent)، یک محیط (Enivronment) و یک مکانیسم بازخورد برای هدایت اقدامات عامل است. عامل یاد میگیرد که اقداماتی را در محیط انجام دهد تا سیگنال پاداش تجمعی را به حداکثر برساند. این سیگانال پاداش جمعی بهعنوان نیروی محرکه برای یادگیری عمل میکند.
یادگیری تقویتی یا Reinforcement Learning چیست؟
یادگیری تقویتی به عنوان یک گرایش از یادگیری ماشین است که از روانشناسی رفتارگرایی الهام میگیرد. این روش بر رفتارهایی تمرکز دارد که ماشین باید برای بیشینه کردن پاداشش انجام دهد. این مسئله، با توجه به گستردگیاش، در زمینههای گوناگونی بررسی میشود. مانند: نظریه بازیها، نظریه کنترل، تحقیق در عملیات، نظریه اطلاعات، سامانه چندعامله، هوش ازدحامی، آمار، الگوریتم ژنتیک، بهینهسازی بر مبنای شبیهسازی، همچنین یادگیری تقویتی در اقتصاد و نظریه بازیها بیشتر به بررسی تعادلهای ایجاد شده تحت عقلانیت محدود میپردازد.
مجله هوش مصنوعی پارس اینفوتک
نحوهی عملکرد یادگیری تقویتی
یادگیری تقویتی را میتوان بهعنوان یک حلقه متشکل از اجزای زیر در نظر گرفت:
عامل (Agent): یادگیرنده یا تصمیمگیرندهای که براساس مشاهدههای خود اقداماتی را انجام میدهد.
محیط (Environment): سیستم یا زمینهی خارجی که عامل در آن عمل میکند.
اقدام (Action) : تصمیم یا انتخابی که عامل در پاسخ به یک حالت اتخاذ میکند.
پاداش (Reward): سیگنال بازخوردی که خوبی یا مطلوبیت عمل عامل را ارزیابی میکند.
حالت (State): پیکربندی یا نمایش فعلی محیط در یک زمان معین.
خطمشی (Policy): استراتژی یا رویکردی که عامل برای انتخاب اقدامات براساس حالتهای مشاهدهشده به کار میگیرد.
یادگیری تقویتی یک الگوی یادگیری است که در آن یک عامل یاد میگیرد که با تعامل با یک محیط تصمیمهای متوالی بگیرد. عامل براساس اقدامات خود بازخوردی را در قالب پاداش یا جریمه دریافت میکند. هدف این الگوریتم ها یادگیری یک خطمشی بهینه است که پاداشهای تجمعی را در طول زمان به حداکثر میرساند. عامل ازطریق آزمونوخطا محیط را بررسی میکند، اقداماتی را براساس وضعیت فعلی آن انجام میدهد و بازخورد دریافت میکند. از این بازخورد برای بهروزرسانی خطمشی خود و اتخاذ تصمیمهای بهتر در آینده استفاده میکند. این الگوریتمهای اغلب از توابع یا value functions برای تخمین پاداشها یا مقادیر موردانتظار مرتبط با حالات و اقدامات مختلف استفاده میکنند که عامل را قادر میکند تواناییهای تصمیمگیری خود را یاد بگیرد و بهبود بخشد. با هر تعامل و یادگیری مکرر، خطمشی عامل بهتدریج بهسمت یک راهحل بهینه همگرا میشود و به رفتار هوشمندانه و سازگار در محیطهای پیچیده و پویا میانجامد.
یادگیری تقویتی چطور کار میکند؟
مکانیسم آموزشی پشت یادگیری تقویتی، سناریوهای زیادی از دنیای واقعی را منعکس میکند. به عنوان مثال، آموزش حیوانات خانگی را از طریق ارائه پاداش به آنها در نظر بگیرید.
مثال اول نحوه کار یادگیری تقویتی
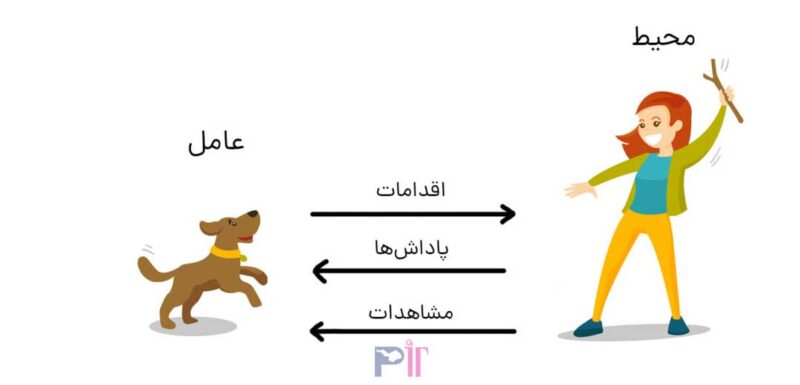
هدف در این مورد آموزش سگ (عامل) برای تکمیل یک کار در محیط است که شامل محیط اطراف سگ و همچنین مربی میشود. ابتدا مربی دستور یا نشانهای را صادر میکند که سگ آن را میبیند (Observation یا مشاهده). سپس سگ با انجام یک اقدام به دستور مربی پاسخ میدهد. اگر عمل نزدیک به رفتار مورد انتظار باشد، مربی احتمالا پاداشی مانند غذا یا اسباببازی به او میدهد. در غیر این صورت پاداشی به سگ تعلق نمیگیرد.
در ابتدای آموزش، سگ احتمالا اقدامات اشتباهی مانند غلت زدن در زمانی که فرمان داده شده «بنشین» انجام میدهد؛ زیرا سعی دارد مشاهدات خاص را با اقدامات و پاداشها مرتبط کند. این ارتباط یا الگوبرداری بین مشاهدات و اقدامات خطمشی (Policy) نامیده میشود. از دیدگاه سگ حالت ایدهآل این است که به هر نشانهای به درستی پاسخ دهد، بهطوری که تا حد امکان پاداش بگیرد. بنابراین تمام معنای آموزش یادگیری تقویتی این است که ذهن سگ را به گونهای آموزش دهید که رفتارهای مورد نظر را بیاموزد و پاداشهای دریافتی را به حداکثر برساند. پس از اتمام آموزش، سگ باید بتواند صاحبش را مشاهده کند و اقدامات مناسب را انجام دهد. بهعنوان مثال، با استفاده از آموزشهای پیشین و ذهنیت صحیح کنونیاش، زمانی که دستور «نشستن» داده میشود، بنشیند. با اجرای صحیح دستورات، سگ قطعا پاداش دریافت میکند.
مثال دوم نحوه کار یادگیری تقویتی
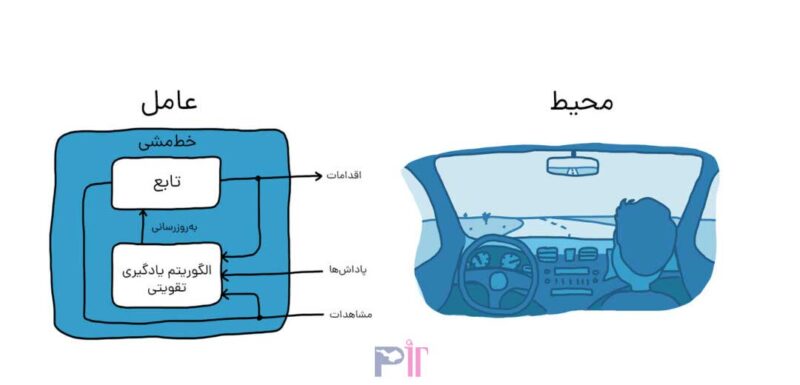
هدف این است که کامپیوتر (عامل) خودرو را با یادگیری تقویتی در محل صحیح پارک کند. در مثال آموزش سگ آنچه در خارج از عامل قرار دارد، محیط نامیده میشود، در این مثال نیز محیط میتواند شامل حرکت وسیله نقلیه در خیابان، حرکت وسایل نقلیه دیگری که ممکن است در نزدیکی باشند، شرایط آب و هوایی و غیره باشد. در طول تمرین، عامل از خواندن دادهها که توسط حسگرهایی مانند دوربینها، جیپیاس و لیدار بهعنوان مشاهدات دریافت میشوند برای تولید فرمانهایی نظیر ترمز و شتاب (عملکرد) استفاده میکند. برای یادگیری نحوه انجام اقدامات صحیح در مقابل مشاهدات (تنظیم خطمشی یا Policy)، کامپیوتر بارها سعی میکند وسیله نقلیه را با استفاده از فرآیند آزمون و خطا پارک کند. پس از انجام اقدام صحیح توسط عامل، یک سیگنال پاداش ارسال میشود تا این پیام را برساند که عمل بهدرستی انجام شده و فرآیند یادگیری باید ادامه یابد.
تفاوت یادگیری تقویتی با سایر روشهای یادگیری ماشین
یادگیری تقویتی را میتوان شاخهای مجزا در یادگیری ماشین در نظر گرفت؛ هرچند شباهتهایی هم با سایر روشهای یادگیری ماشین دارد. برای دریافتن این شباهتها و تفاوتها بهتر است نگاهی به سایر روشهای یادگیری ماشین هم نگاهی داشته باشیم.
یادگیری نظارتی (supervised learning)
در یادگیری نظارتی، الگوریتمها با استفاده از یک سری داده برچسبدار آموزش داده میشوند. این الگوریتمها فقط ویژگیهایی را یاد میگیرند که در دیتاست مشخص شده است و به آنها هدف یا target گفته میشود. در واقع «هدف» در این نوع یادگیری کاملا تعریف شده است و نمونههای از داده و پاسخ درست در اختیار مدل قرار میگیرد تا با استفاده از آنها بتواند هر دادهی جدیدی را که میبیند برچسب بزند. یکی از رایجترین کاربردهای یادگیری نظارتی، مدلهای تشخیص تصویر است. این مدلها یک مجموعه عکس برچسبدار دریافت میکنند و یاد میگیرند بین ویژگیهای متداول آنها تمایز قائل شوند. به عنوان مثال با دریافت عکسهایی از صورت انسانها، میتوانند اجزای صورت را تشخیص دهند. یا بین دو یا چند حیوان تمایز قائل شوند.
یادگیری نیمه نظارتی (semi supervised learning)
این روش، روشی بینابینی است. توسعهدهندگان، یک مجموعه نسبتا کوچک از دادههای برچسبدار و یک مجموعه بزرگتر از داده بدون برچسب آماده میکنند. سپس از مدل خواسته میشود، براساس چیزی که از دادههای برچسبدار یاد میگیرد، درمورد دادههای بدون برچسب هم پیشبینی انجام دهد و در نهایت دادههای بدون برچسب و برچسبدار را به عنوان یک مجموعه داده کل درنظر بگیرد و نتیجهگیری نهایی را انجام دهد.
یادگیری غیر نظارتی (unsupervised learning)
در یادگیری غیرنظارتی، فقط دادههای بدون برچسب در اختیار الگوریتم قرار داده میشود. این الگوریتمها بدون اینکه مستقیم به آنها گفته شده باشد دنبال چه ویژگیها بگردند، براساس مشاهده های خودشان آموزش میبینند. نمونهای از کاربرد این نوع یادگیری، خوشهبندی مشتریها است.
یادگیری تقویتی (Reinforcement Learning)
رویکرد یادگیری تقویتی کاملا متفاوت است. در این روش، یک عامل در محیط قرار میگیرد تا با آزمون و خطا یاد بگیرد کدام کارها مفید و کدام کارها غیرمفید هستند و در نهایت به یک هدف مشخص برسد. از این جهت که درمورد یادگیری تقویتی هم هدف مشخصی از یادگیری وجود دارد، میتوان آن را شبیه یادگیری نظارتی دانست. اما وقتی که اهداف و پاداشها مشخص شدند، الگوریتم به صورت مستقل عمل میکند و نسبت به یادگیری نظارتی تصمیمات آزادانهتری میگیرد. به همین علت است که برخی یادگیری تقویتی را در دسته نیمه نظارتی جای میدهند. اما با توجه به آنچه گفته شد، منطقیتر این است که یادگیری تقویتی را به عنوان یک دسته جدا در یادگیری ماشین در نظر گرفت.
کاربردهای یادگیری تقویتی
یادگیری تقویتی کاربردهای متعددی در حوزههای مختلف پیدا کرده است، از جمله:
رباتیک: یادگیری تقویتی رباتها را قادر میکند تا عملها و حرکتهای خود را براساس آزمونوخطا یاد بگیرند و بهبود بخشند و به آنها اجازه میدهد در محیطهای پیچیده حرکت کنند یا اشیا را دستکاری کنند.
بازی: این الگوریتمها در انجامدادن بازیهای پیچیده، مانند شطرنج، Go و بازیهای ویدئویی، به موفقیت چشمگیری دست یافتهاند و در برخی موارد از عملکرد انسان پیشی گرفتهاند.
وسایل نقلیه خودمختار: تکنیکهای یادگیری تقویتی را میتوان برای آموزش خودروهای خودران برای تصمیمگیری بهینه در زمان واقعی به کار برد که به حملونقل ایمنتر و کارآمدتر میانجامد.
مدیریت منابع: این نوع یادگیری میتواند برای بهینهسازی تخصیص منابع، زمانبندی و تصمیمگیری در حوزههایی مانند مدیریت انرژی، لجستیک و ارتباطات استفاده شود.
محدودیتهای یادگیری تقویتی
درحالیکه یادگیری تقویتی قابلیتهای قدرتمندی را ارائه میکند، با محدودیتهای خاصی نیز همراه است:
کارایی نمونه (Sample Efficiency): الگوریتمهای RL معمولاً به مقدار قابل توجهی از تعامل با محیط برای یادگیری سیاستهای بهینه نیاز دارند و از نظر محاسباتی گران و وقتگیر هستند.
تریدآف اکتشاف و بهرهبرداری (Exploration-Exploitation Trade-off): ایجاد تعادل میان اکتشاف اقدامات جدید و بهرهبرداری از دانش آموختهشده چالشبرانگیز است؛ زیرا اکتشاف بیشازحد ممکن است تصمیمگیری بهینه را به تاخیر بیندازد و بهرهبرداری بیشازحد ممکن است به راهحلهای غیربهینه بینجامد.
مهندسی پاداش (Reward Engineering): طراحی توابع پاداش مناسب که با رفتار مدنظر هماهنگ باشد میتواند پیچیده باشد و تعریف پاداشهایی که بهطور دقیق هدفهای عامل را نشان میدهند، یک کار غیرضروری است.
ملاحظههای اخلاقی (Ethical Considerations): الگوریتمهای یادگیری تقویتی میتوانند رفتارهای نامطلوب یا مضر را بیاموزند، اگر بهدقت طراحی نشده باشند، بهطور بالقوه نگرانیهای اخلاقی و نیاز به نظارت دقیق را افزایش میدهند.
انواع یادگیری تقویتی
با توجه به رویکردهای متفاوتی که الگوریتمهای یادگیری عمیق در سه مرحله جمعآوری داده، تخمین تابع ارزش و بهینهسازی سیاست در پیش میگیرند، میتوان آنها را از مناظر مختلف دستهبندی کرد که در ذیل به دستهبندیها رایج در این حوزه اشاره میگردد:
الگوریتمهای یادگیری تقویتی بین دو فعالیت جمعآوری داده و بهبود سیاست دائما در تناوب هستند. سیاستی که برای جمعآوری داده استفاده میشود ممکن است با سیاست عامل در حین آموزش متفاوت باشد. به این رویکرد Off-policy میگویند. در رویکرد Off-policy سیاست بهینه بدون در نظر گرفتن اقدامات عامل و یا انگیزه او برای اقدام بعدی تعیین میشود. در مقابل رویکرد On-policy، از همان سیاستی که در آموزش استفاده شده برای جمعآوری داده نیز استفاده میگردد. به بیانی دیگر، این رویکرد به سیاستهایی که عامل قبلاً در تصمیمگیریها استفاده کرده، توجه کرده و سعی در ارزیابی و بهبود آنها میکند.
الگوریتمهای بدون مدل دربرابر الگوریتمهای مبتی بر مدل: در خیلی از اوقات وضعیتهای مسأله دارای ابعاد بالایی است. در چنین شرایطی، تابع انتقال نیاز به برآورد توزیع احتمال روی هر یک از این حالتها است. همچنین به یاد داشته باشید که احتمالات انتقال باید در هر مرحله محاسبه شوند. در حال حاضر، انجام این کار با قابلیتهای سختافزاری فعلی تقریبا غیرقابل حل است. برای رویارویی با این چالش یک دستهبندی از مسائل یادگیری تقویتی ارائه شده است: در شرایطی که تلاش طراح صرف یادگیری مدلی از شرایط و محیط اطراف میشود، میتوانیم بگوییم رویکرد مبتنی بر مدل را در پیش گرفته است. به عنوان نمونه، مجددا بازی آجرشکن آتاری را در نظر بگیرید. طراح از یادگیری عمیق برای یادگیری تابع انتقال و تابع پاداش بهره میگیرد. وقتی روی یادگیری این مسائل تمرکز میشود. به اصطلاح در حال یادگیری مدلی از محیط هستیم که ما از این مدل برای دستیابی به تابعی به نام سیاست ( ) استفاده میکنیم. تابع سیاست، مشخص مینماید که وقتی محیط در وضعیت است، عامل با چه احتمالی اقدام را برمیگزیند. اما با افزایش تعداد وضعیتها و اقدامها، الگوریتمهای مبتنی بر مدل کارآمدی خود را از دست میدهند. از سوی دیگر، الگوریتمهای بدون مدل درواقع مبتنی بر روش آزمون و خطا هستند و براساس نتیجه آن، دانش خود را بهروزرسانی میکنند. این نوع از الگوریتمها برای مواقعی مناسب هستند که مدلسازی محیط بسیار سخت باشد و طراح ترجیح میدهد الگوریتمی را مورد استفاده قرار دهد که بهجای تلاش برای یادگیری مدل محیط، مستقیماً از تجربیات یاد بگیرد. این رویکرد بسیار شبیه روشی است که انسانها اکثر وظایف خود را مبتنی بر آن یاد میگیرند. به عنوان نمونه، راننده ماشین برای انجام رانندگی، قوانین فیزیک حاکم بر ماشین را نمیآموزد، اما یاد میگیرد که بر اساس تجربه خود از نحوه واکنش ماشین به اقدامات مختلف، تصمیم بگیرد. از مزیتهای این رویکرد، عدم نیاز به فضایی برای ذخیره ترکیبات احتمالی وضعیتها و اقدامها خواهد بود.
رویکر مبتنی بر ارزش و یا مبتنی بر سیاست: اکثر مدلهای بدون مدل از دو رویکرد ارزش محور و یا سیاست محور استفاده میکنند. در رویکرد سیاست محور، هدف بهینهسازی تابع سیاست است بدون اینکه به تابع ارزش کار داشته باشیم. به بیانی دیگر عامل یک تابع سیاست را میآموزد، آنرا در حین یادگیری در حافظه نگه میدارد و سعی میکند هر وضعیت را به بهترین اقدام ممکن نگاشت کند. لازم به ذکر است سیاستها ممکن است قطعی (برای یک وضعیت، همیشه اقدام مشابهی را باز میگرداند) و یا تصادفی (برای هر اقدام یک توزیع احتمالی در نظر میگیرد) باشند. در رویکرد ارزش محور، برخلاف رویکرد سیاستمحور که به تابع ارزش کاری ندارد، هدف بهینهسازی تابع ارزش خواهد بود. به عبارت دیگر، عامل اقدامی را انتخاب مینماید که برآورد میکند بیشترین پاداش را در آینده دریافت خواهد کرد.
معروفترین الگوریتمهای یادگیری تقویتی
چندین الگوریتم و روش تصمیمگیری در یادگیری تقویتی وجود دارد که تفاوت آنها عمدتا به دلیل استراتژیهای مختلفی است که برای کشف محیط خود استفاده میکنند. در ادامه به برخی از پرکاربردترین روشهای تصمیمگیری در یادگیری تقویتی اشاره خواهیم کرد.
مونت کارلو (Monte Carlo)
این روش نوعی الگوریتم یادگیری تقویتی است که از تجربه یاد میگیرد. عامل شروع یادگیری را با پاداشهایی که برای اقدامات مختلف دریافت میکند، کاوش تصادفی محیط و جمعآوری دادهها انجام میدهد. سپس از این دادهها برای تخمین ارزش هر جفت حالت- عمل استفاده میشود. در نهایت عامل اقدامی که بالاترین ارزش تخمینی را در پی دارد، انتخاب میکند. تصور کنید سعی دارید بهترین راه را برای انجام یک بازی ویدیویی جدید بیابید. اما قوانین و اینکه کدام اقدامات منجر به بالاترین امتیاز میشوند را نمیدانید.
مونت کارلو در یادگیری تقویتی مانند این است که پس از چندین بار انجام بازی از دوستان خود راهنمایی بخواهید. شما بازی میکنید، اقداماتی را انجام میدهید و نتایج اقدامات خود را میبینید. هر بار که بازی را تمام میکنید، از دوستانتان میپرسید که در مورد اقدامات و نتیجه بازیتان چه فکر میکنند. در طول زمان، با جمعآوری نظرات آنها پس از بازیهای زیاد، شروع به دریافت ایدههای خوب میکنید که کدام اقدامات منجر به امتیازات بیشتر میشوند.
به عبارت فنیتر، مونت کارلو توسط یادگیری از تجربیات قبلی با شبیهسازی بسیاری از قسمتهای تعامل با محیط، کسب حداکثر پاداش را یاد میگیرد. پس از هر اپیزود از بازخوردی که از آن تجربیات دریافت کردهاید، استفاده میکنید تا درک خود را از اینکه کدام اقدامات خوب هستند و کدامها خوب نیستند، بدون نیاز به دانستن قوانین دقیق بازی از همان ابتدا، بهبود ببخشید.
روشهای تفاوت زمانی (Temporal Difference)
روشهای تفاوت زمانی نوعی الگوریتم یادگیری تقویتی هستند که از تفاوت بین پاداش مورد انتظار و پاداش واقعی یاد میگیرند. عامل شروع یادگیری را با تخمین ارزش هر جفت حالت- عمل انجام میدهد. سپس این تخمینها را پس از هر تعامل با محیط بهروز میکند. بهروزرسانی بر اساس تفاوت بین پاداش مورد انتظار و پاداش واقعی انجام میشود.
بهطور مثال تصور کنید در حال پختن کلوچه هستید؛ اما هنوز زمان دقیق پخت را نمیدانید. بعد از پخته شدن تعدادی کلوچه، شما طعم و بافت هر کدام را با آنهایی که در دفعات قبلی پخته شده بودند، مقایسه میکنید. سپس تخمین خود را با در نظر گرفتن تفاوت دسته فعلی با موارد قبلی بهروز میکنید. در این مثال شما عامل هستید و نحوه پخت کلوچهها اعمال. حال در یادگیری تقویتی، هوش مصنوعی عامل است. با گذشت زمان و تکرارهای بیشتر، تخمین عامل هوش مصنوعی از بهترین زمان پخت دقیقتر میشود که منجر به نتایج بهتر میشود.
روشهای گرادیان خطمشی (Policy Gradient)
نوعی دیگر از الگوریتم یادگیری تقویتی که یک خطمشی را یاد میگیرند. خطمشی تابعی است که از حالتها به اقدامات صحیح میرسد. این شیوه با تخمین پاداش مورد انتظار با توجه به هر خطمشی، گرادیان را بهروز میکند.
بهطور مثال، در آموزش سگ، تصور کنید که به او یاد میدهید که بنشیند، اما گاهی اوقات او خیلی آهسته مینشیند یا اصلا نمینشیند. با استفاده از گرادیان خطمشی، میتوانید بر اساس میزان پیروی از خطمشی، به سگ پاداشهای مختلفی بدهید. بهعنوان مثال، اگر سگ سریع بنشیند، میتوانید غذای زیادی به او بدهید، اما اگر آرام بنشیند، میتوانید غذای کمی در اختیارش بگذارید. این تفاوت در پاداشها به سگ کمک میکند تا بفهمد کدام اقدامات بهتر است و او را تشویق میکند تا رفتار مورد انتظار را بهطور موثرتری انجام دهد. با تکرار مکرر این فرآیند، سگ به تدریج یاد میگیرد که این سیاست را بهتر و بیشتر دنبال کند. بهطور مشابه، در هوش مصنوعی، ما مدل را با مثالهای زیادی آموزش میدهیم و زمانی که تصمیمهای خوب میگیرد به آن پاداش میدهیم و وقتی تصمیمات بد میگیرد، جریمه میکنیم. این کار به هوش مصنوعی اجازه میدهد تا سیاست خود را بهبود بخشد و در موقعیتهای مختلف تصمیمات بهتری بگیرد.
هر کدام از این روشها از نظر پیچیدگی متفاوتند و برای انواع مختلفی از مشکلات بر اساس ماهیت محیط و اطلاعات موجود مناسب هستند. علاوه بر روشهای فوق، تعدادی تکنیک دیگر وجود دارد که میتوان از آنها برای بهبود فرآیند تصمیمگیری در یادگیری تقویتی استفاده کرد. این تکنیکها شامل موارد زیر میشوند:
اکتشاف حریصانه اپسیلون: تکنیکی است که به عامل اجازه میدهد در عین حال که پاداشهای بهینه را یاد میگیرد، محیط را هم کاوش کند. عامل با کاوش تصادفی محیط یادگیری را شروع میکند؛ اما با یادگیری بیشتر در مورد محیط حریصتر میشود و اقدامی را با بالاترین ارزش تخمینی انتخاب میکند.
پاسخ بر اساس تجربه: تکنیکی که تجربیات عامل را در یک بافر ذخیره میکند. این تجربیات ذخیرهشده به عامل اجازه میدهد تا با یادگیری از تعداد بیشتری از تجربیات بهطور کارآمدتری فرآیند آموزش را طی کند.
شکلدهی پاداش: این تکنیک پاداشهای موجود در محیط را تغییر میدهد تا مشکل را آسانتر حل کند. این کار را میتوان با افزودن پاداش برای رفتارهای دلخواه یا با حذف پاداش برای رفتارهای ناخواسته انجام داد.
روشهای مبتنی بر ارزش (Value-Based)
این روشها بر میانگین ارزشهای آموختهشده تمرکز میکنند. روشهای مبتنی بر ارزش شامل جدولی از مقادیر هستند که عامل باید آنها را فرا بگیرد. این مقادیر نشاندهنده پاداش مورد انتظار برای انجام اقدامی خاص در یک وضعیت بهخصوص است. مقادیر در این روش پس از هر تعامل با محیط، بر اساس تفاوت بین پاداش مورد انتظار و پاداش واقعی بهروز میشوند. این بهروزرسانی به عامل اجازه میدهد تا از تعداد بیشتری از حالتها و اقدامات درس بگیرد و نتایج بهتری را به موقعیتهای جدید تعمیم دهد.
یادگیری تقویتی مبتنی بر ارزش مانند داشتن یک نقشه گنج است که در آن ارزش مکانهای مختلف را با حفاری و یافتن پاداش میآموزید.
تصور کنید در حال کاوش در یک جزیره جدید به دنبال گنجینههای پنهان هستید. شما نقشهای دارید که میگوید کدام مکانها ممکن است گنج داشته باشند. هر بار که در یکی از آن مکانها مشغول حفاری میشوید، مقداری طلا پیدا میکنید. با گذشت زمان، متوجه میشوید که نقاط خاصی روی نقشه شما ارزشمندتر هستند؛ زیرا طلای بیشتری دارند.
یادگیری تقویتی مبتنی بر ارزش مشابه همین روش است. در این مورد شما کاوشگر یا عامل هستید، جزیره محیط است، نقشه درک عامل از اینکه کدام اقدامات یا تصمیمات ارزشمند هستند و طلا پاداشهایی است که عامل دریافت میکند. کاوشگر با انجام مکرر اقدامات، دریافت پاداش و بهروزرسانی درک خود از بهترین اقدامات برای به حداکثر رساندن پاداش، میآموزد که کدام اقدامات یا تصمیمات ارزشمندتر هستند. در یادگیری تقویتی مبتنی بر ارزش، عامل بهترین اقدامات را برای به حداکثر رساندن پاداشها بر اساس تعامل خود با محیط میآموزد.
الگوریتم Q-learning: در Q-learning، الگوریتم بدون سیاست عمل میکند و یا همانطور که در بخش قبل گفته شد یک الگوریتم off-policy است. این الگوریتم تابع ارزش را یاد میگیرد؛ به این معنی که انجام عمل a در حالت s چقدر نتایج مثبت دارد. روند کار در الگوریتم Q-learning شامل مراحل زیر میشود
جدول Q یا Q-table ایجاد میشود. در این جدول، تمام حالتها، تمام عملهای ممکن و پاداشهای مورد انتظار آمده است.
یک عمل انتخاب میشود.
پاداش محاسبه میشود.
جدول Q-table به روز میشود.
Deep Q: همانطور که از اسمش پیداست، همان Q-learning است که از شبکههای عصبی عمیق استفاده میکند. لزوم استفاده از شبکههای عصبی هنگامی است که با محیطهای بزرگ با تعداد حالتهای زیاد سروکار داریم؛ در چنین حالتی، به روز کردن Q-table کار آسانی نخواهد بود. به همین خاطر به جای تعریف مقادیر ارزش برای هر حالت، با استفاده از شبکه عصبی مقدار ارزش را برای هر عمل و حالت تخمین میزنیم.
SARSA: الگوریتم SARSA، یک الگوریتم سیاست محور محسوب میشود. در این الگوریتمها، عملی که در هر حالت انجام میشود و خود یادگیری بر اساس سیاست مشخصی است. تفاوت عمدهای که الگوریتم SARSA با الگوریتم Q-learning دارد این است که برای محاسبه پاداش حالتهای بعدی، نیازی به داشتن تمام Q-table نیست.
اصطلاحات مهم در یادگیری تقویتی
عامل (Agent): عامل موجودی است که در محیط به اکتشاف و جستجو میپردازد تا با شناخت محیط بتواند متناسب با شرایط تصمیمگیری و عمل کند.
محیط (Environment): شرایطی است که عامل در آن حضور دارد، یا توسط آن احاطه شده است. در یادگیری تقویتی، محیط تصادفی (stochastic) است. به این معنی که محیط به خودی خود، تصادفی است.
عمل (Action): عمل، حرکتهایی است که توسط عامل در محیط انجام میشود.
حالت (State): حالت، شرایطی است که بعد از هر عمل، از طرف محیط بازگردانده میشود.
پاداش (Reward): بازخوردی است که از طرف محیط به عامل داده میشود تا عملی که انجام داده ارزیابی شود.
سیاست (Policy): سیاست یک نوع استراتژی است که عامل براساس آن، از روی حالت فعلی محیط، عمل بعدیاش را انجام میدهد.
ارزش (Value): میزان ارزش ایجاد شده در بلند مدت است و میتواند با پاداش کوتاه مدت متفاوت باشد. به این معنی که گاهی برخی از تصمیمها در کوتاهمدت پاداشی به همراه ندارند یا حتی پاداش منفی دارند، اما در جهت رسیدن به هدف نهایی مساله هستند.
![]()
![]()
![]()
شما دوره آموزشی هم دارید برای یادگیری تقویتی؟
از کجا باید شروع کنم
خیر فعلا دوره آموزشی نداریم
اما یکسری اطلاعات رو براتون ایمیل کردیم
امیدوارم مفید باشه
عالی و کاربردی